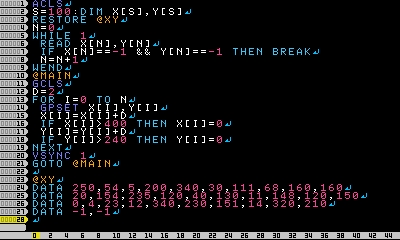
例えば
READ N
DATA 1,2,3,4
とすると単に
N=1
と同じ処理になるんですが、READ命令とDATA文の真価が発揮されるのはループ処理の中で繰り返す事でN=1がN=2やN=3に変化させれるって事なんですな。
だにえるさんが説明してくれてますけど、RESTORE命令とラベルを組み合わせる事で読み込むデータの位置を操作出来るので
プログラム中で使う定数の使い回しが楽になったりもするんですな。
配列は「 DIM 配列変数名[個数] 」で定義することができて
「 配列変数名[番号] 」を変数名として使えるのです。
DIM A[10] と定義すると A[0] を変数名として使えます
カッコがあるけどそれが変数名として使えます
このカッコの中の数値は別の変数にしても使えるので
DIM A[10]
I=3
A[I]=999
という感じでも使えます
VAR A0: VAR A1 とどんどん書いて行くのが大変なのと、番号に別の変数が使えるという理由で DIM A[2] として配列にしたほうが便利なのです。
READとDATAには、実は「読み込むDATAの位置」というのが内部でこっそり存在しています。
READ は 1回実行するごとに、「読み込むDATAの位置」にある DATAの値を1つ読み込んで、「読み込むDATAの位置」を次のDATAの値にします
これによって次のREADは次のDATAの値が読めます(「次のDATA」ではなく「次のDATAの値」です)
ちなみに「読み込むDATAの位置」は起動時は最初のDATAの値で、RESTORE 命令でラベル位置に変更できます
コレを踏まえて、配列と組み合わせるとこんなことが出来ます。
READ N
DIM A[N]
FOR I=0 TO N-1
READ A[I]
NEXT
DATA 10 '個数
DATA 9,8,7,6,5
DATA 4,3,2,1,0