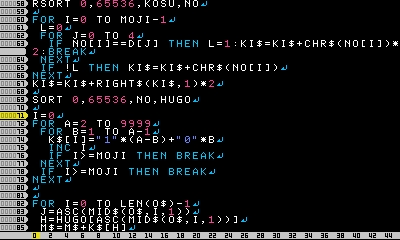
プチコン3号 SmileBASIC コミュニティ投稿あまさと しおん ShionAmasato2015/04/24 18:50:55圧縮PRGの核心部1 2進符号を生成するところ1そうだね 12返信プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[1]親投稿あまさと しおん ShionAmasato2015/4/24 18:5871行目~ PRINTはさんで実行すると分かるけど最初は2文字("10")でどんどん長くなる0そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[2]親投稿れい rei-nntnd2015/4/24 19:03ハフマンつかってるのかな トピひらくまえ12進符号にみえてビビった 2そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[3]親投稿あまさと しおん ShionAmasato2015/4/24 19:09ハフマンを意識したなにか というのだろうか 多い文字ほど短い符号がつくのは確か ただ木とかいう概念はない 1 文字の種類とそれぞれの数を数える 2 種類を多い順にSORTする 3 文字列から2進数の符号列を生成 4 65536進数に変換0そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[4]親投稿れい rei-nntnd2015/4/24 19:11変形シャノン符号か プチコンならハフマンより高速にできるかもしれない1そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[5]親投稿れい rei-nntnd2015/4/24 19:24これコードの量どれくらいなのかな あまり長くないようだったら俺の作ったのと合わせてみたいなぁ あまさと氏のはエントロピー系の圧縮で、俺のはLZSSだから履歴系の圧縮。 方式が違うから2回圧縮してもいけるはずなんだよね 画像はLZSSが強いけど文字列はエントロピー系が強いので 両方あったら汎用性高くなるんじゃないかなぁ1そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[6]親投稿あまさと しおん ShionAmasato2015/4/24 19:26170行で折り返す行は少ない ただ文字列配列の大量消費とOPTION DEFINTがある それとデータ量によっては化ける0そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[7]親投稿あまさと しおん ShionAmasato2015/4/24 19:31あと致命的な制限事項 文字種9998種類くらいに制限(outofmemory防止、圧縮可能なデータ量は多分文字種に負の相関)0そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[9]親投稿あまさと しおん ShionAmasato2015/4/24 19:33うん、どのくらいの大きさから生じるかは検証してない0そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[10]親投稿れい rei-nntnd2015/4/24 19:34さぁ楽しいデバッグの時間だよ1そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[11]親投稿あまさと しおん ShionAmasato2015/4/24 19:37元データ15420文字は化ける そういえばデフォルトプロジェクトからサンプル読むにはどうすればいいんだろう0そうだね プレイ済み2017/11/03 21:46:22に取得
プチコン3号 SmileBASIC コミュニティ返信[12]親投稿あまさと しおん ShionAmasato2015/4/24 19:46/区切りで行けた 7311字 GAME1 ok 10591字 GAME3 ok 28868字 GAME4 すごく遅くて動いてるか心配→案の定OUT 0そうだね プレイ済み2017/11/03 21:46:22に取得